

Building Kumari LLM: A Deep Dive into Our Three-Router Architecture
When We started building Kumari LLM, We knew We wanted to create something different. Not just another AI chat API, but a system that could intelligently route requests, optimize for cost and performance, and provide a seamless experience across multiple AI providers. What emerged was a unique three-router architecture that I believe sets us apart from the competition.
The Problem with Traditional AI APIs
Most AI platforms today follow a simple pattern: you send a request, they route it to a single model, and you get a response. But this approach has fundamental limitations:
- No intelligence in routing: The same model handles everything from code generation to creative writing
- Cost inefficiency: Expensive models for simple tasks, cheap models for complex ones
- Performance bottlenecks: No consideration for latency vs. quality trade-offs
- Provider lock-in: You're stuck with one AI provider's limitations
We wanted to solve these problems by creating an intelligent routing system that could make real-time decisions about which model to use based on the task at hand.
The Three-Router Architecture
Our solution is built around three specialized routers, each named after Sanskrit concepts that reflect their purpose:
Architecture Overview
The following diagram shows how our three routers work together to process user requests:
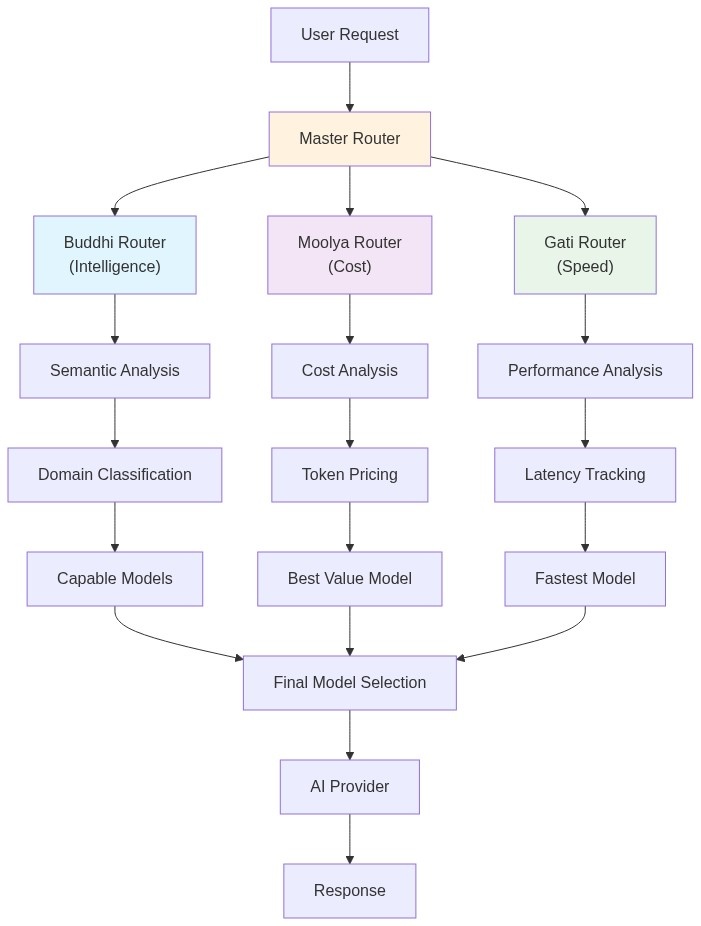
1. Buddhi Router: The Intelligence Layer
Buddhi means "intelligence" or "discernment" in Sanskrit, and that's exactly what this router provides. It's our semantic classifier that analyzes incoming prompts and determines what type of task we're dealing with.
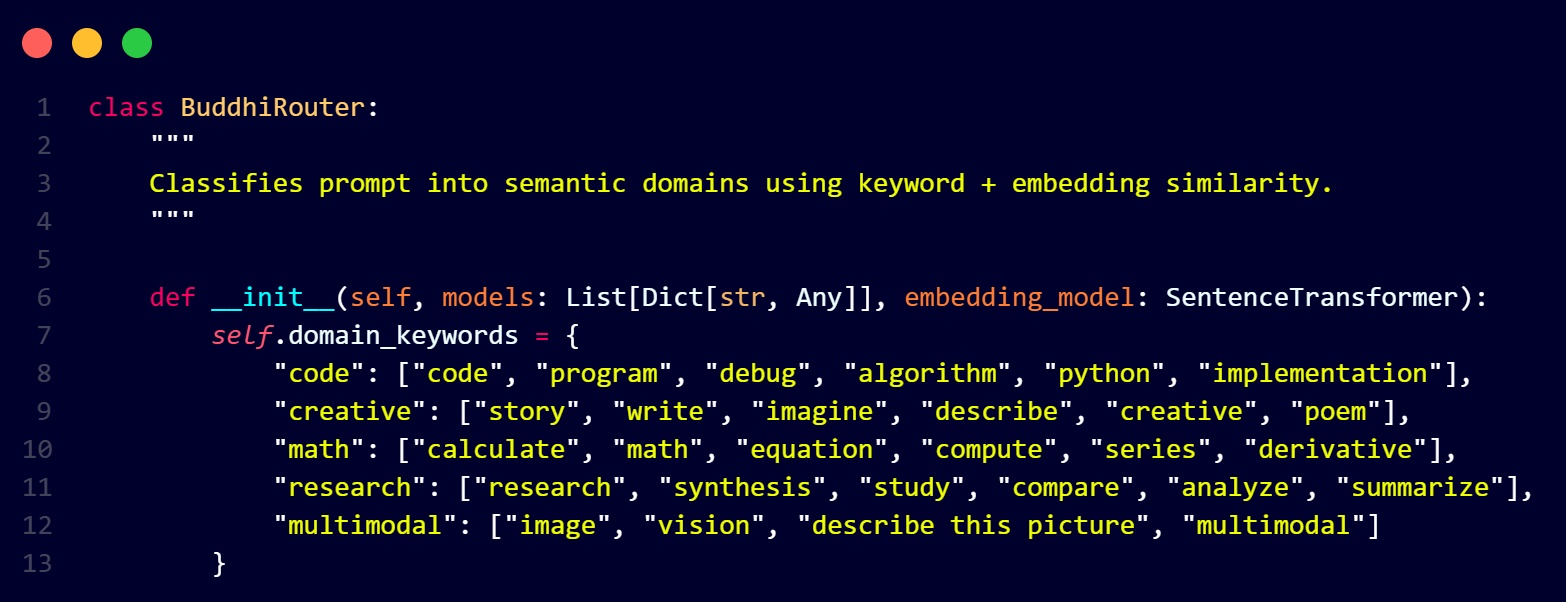
The Buddhi router uses a hybrid approach:
- Keyword matching: Fast, rule-based classification for common patterns
- Semantic embeddings: Deep learning-based similarity matching using sentence transformers
- Domain classification: Maps prompts to specific capability domains
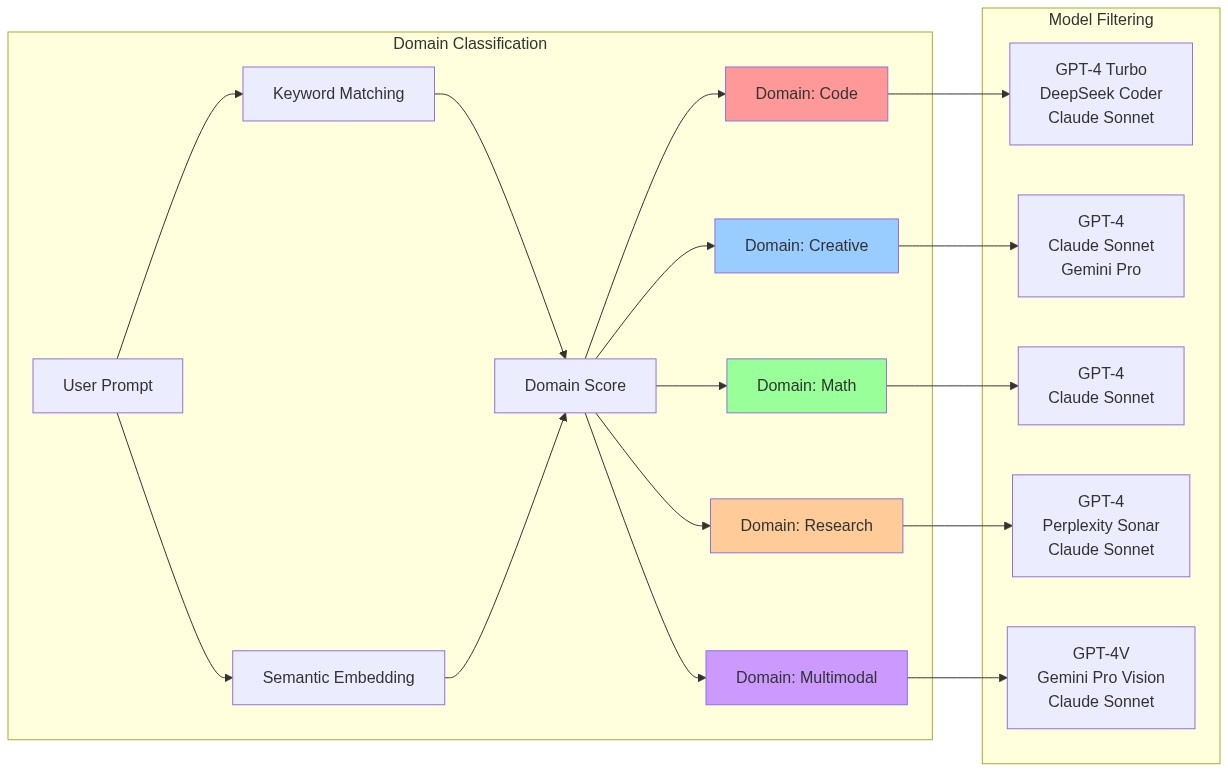
This allows us to identify whether a user wants code generation, creative writing, mathematical computation, research synthesis, or image processing - all in under 5ms.
Domain Classification Flow
Here's how the Buddhi router classifies prompts into different domains:
2. Moolya Router: The Cost Optimizer
Moolya means "value" or "price" in Sanskrit. This router is our financial brain, ensuring we get the best value for every request.
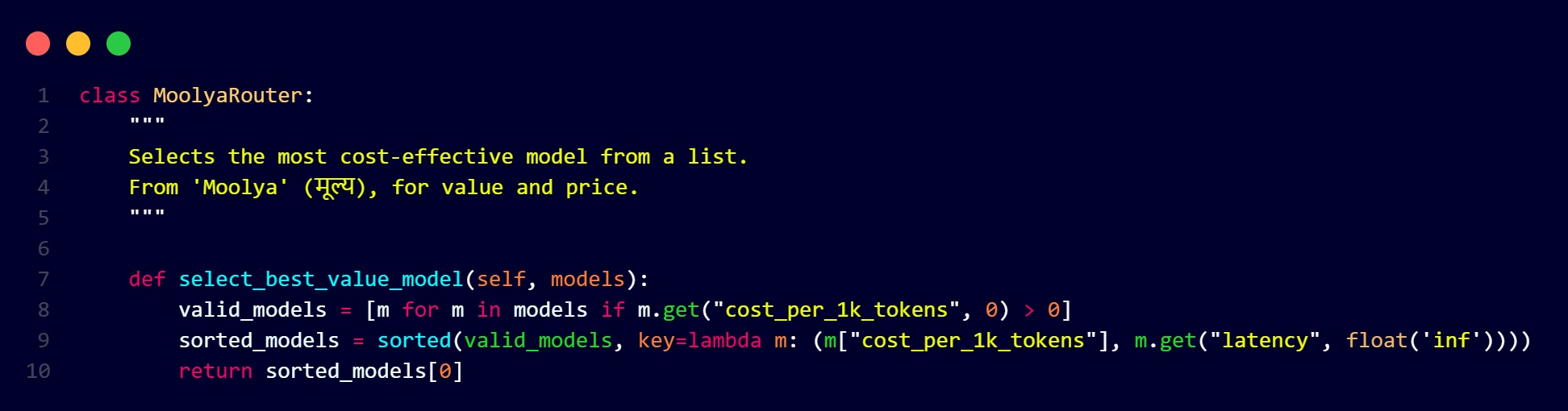
The Moolya router considers:
- Token cost: Direct cost per 1K tokens for each model
- Latency trade-offs: Sometimes faster models cost more, but provide better UX
- Capability matching: Only considers models that can handle the task
- Provider diversity: Spreads load across different AI providers
This means a simple question might get routed to GPT-3.5-turbo (cheap and fast), while complex reasoning goes to GPT-4 (more expensive but more capable).
3. Gati Router: The Performance Optimizer
Gati means "speed" or "velocity" in Sanskrit. This router optimizes for response time and user experience.
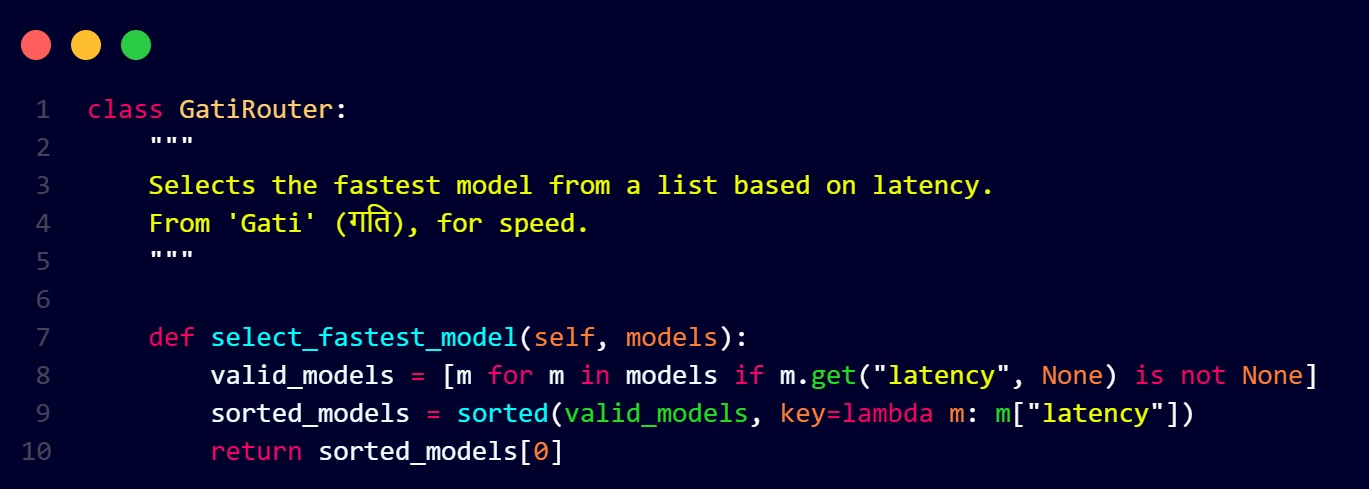
The Gati router tracks:
- Real-time latency: Historical performance data for each model
- Response time optimization: Prioritizes models with proven speed
- Fallback mechanisms: If a fast model fails, it can switch to alternatives
- User experience: Ensures consistent, predictable response times
How the Three Routers Work Together
The magic happens in our master router, which orchestrates all three specialized routers:
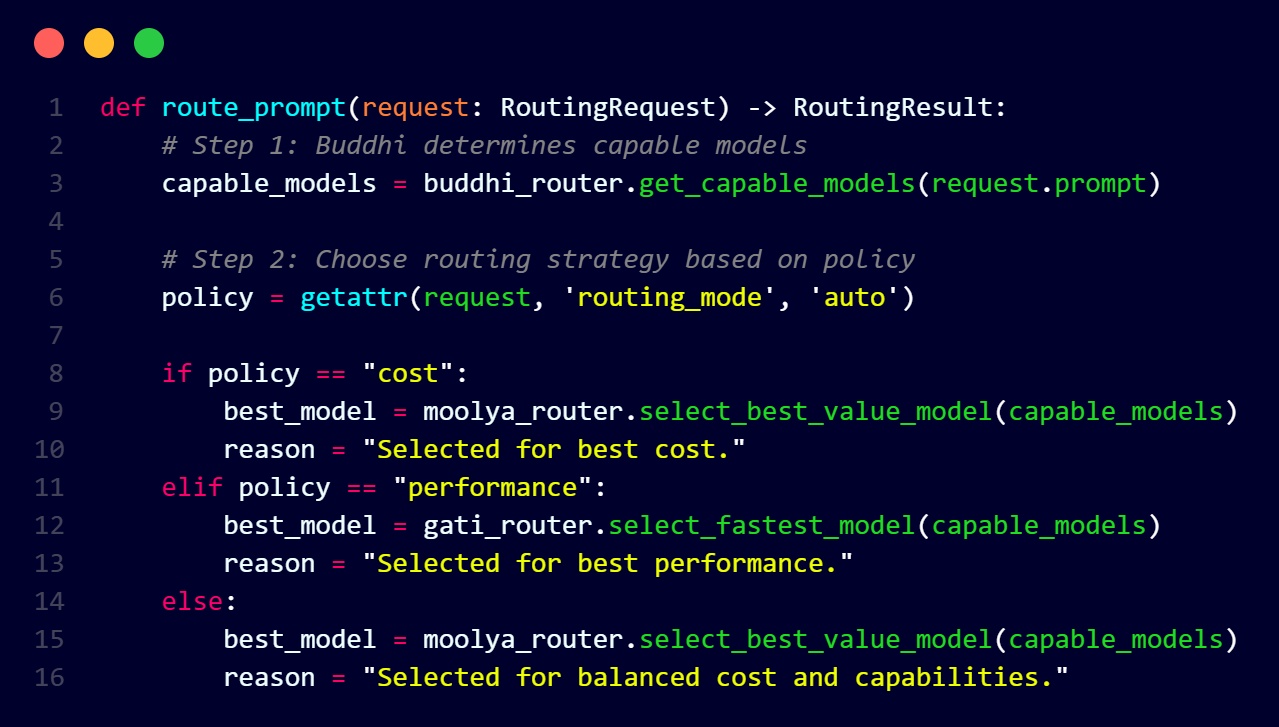
This creates a decision tree:
- Buddhi filters models by capability
- Policy determines optimization strategy
- Moolya or Gati selects the optimal model
- Master router handles the final selection and fallback
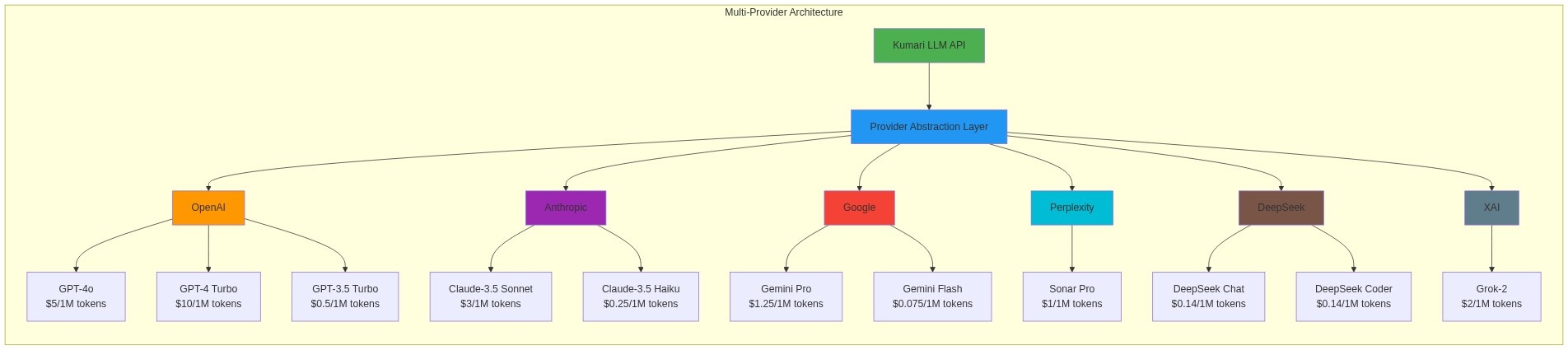
Multi-Provider Support
One of the key advantages of our architecture is seamless multi-provider support. We currently integrate with:
OpenAI
GPT-4, GPT-3.5-turbo, GPT-4o
Anthropic
Claude-3.5-Sonnet, Claude-3.5-Haiku
Gemini Pro, Gemini Flash
Perplexity
Sonar, Sonar Pro
DeepSeek
DeepSeek Chat, DeepSeek Coder
XAI
Grok-2, Grok-3-Mini
Each provider is abstracted through a unified interface, so our routers can make decisions based on capability, cost, and performance rather than being locked into a single provider.
Multi-Provider Architecture
Our provider abstraction layer allows seamless switching between different AI services:
Performance Metrics
Our current performance metrics speak for themselves:
What Makes Us Different
While other platforms offer AI APIs, Kumari LLM provides:
🧠 Intelligent Routing
Automatic model selection based on task type
💰 Cost Optimization
Always choose the most cost-effective model for the job
⚡ Performance Optimization
Prioritize speed when needed
🔄 Multi-Provider
No vendor lock-in, always use the best available model
🧠 Conversation Memory
Intelligent summarization for long conversations
🛡️ Automatic Failover
If one model fails, seamlessly switch to another
📊 Real-time Monitoring
Track performance and automatically blacklist problematic models
🎯 Intelligent Caching
Smart caching with 40-60% hit rates to reduce response times
The Future
This architecture is designed to scale. We're working on:
- Custom Model Training: Fine-tuned models for specific domains
- Advanced Prompt Engineering: Automatic prompt optimization
- Multi-Modal Support: Enhanced image and video processing
- Enterprise Features: Advanced analytics and team management
- API Marketplace: Allow developers to contribute custom models
Conclusion
Building Kumari LLM has been an incredible journey. The three-router architecture wasn't planned from the start - it evolved as I solved real problems users were facing. What started as a simple AI API has become an intelligent system that can adapt to any task, optimize for any constraint, and provide the best possible experience.
The key insight was that AI isn't just about having good models - it's about having the right model for the right task at the right time. Our three-router system makes that possible, and We believe it represents the future of AI API design.