

Shadow Routing in Production (Safely)
Test new models on real traffic without risking real users.
Why Shadow Routing Matters
Rolling out a new model is risky.
- What if latency spikes?
- What if it hallucinates more than your current model?
- What if the cost doubles?
Shadow routing lets you learn from real production traffic while
ensuring your end users see zero impact.
Instead of flipping live traffic to a candidate model and hoping for the
best, you send a copy of requests to one or more candidates in parallel.
Their outputs are logged, scored, and compared, but never shown to the
user.
That means you upgrade models with evidence, not gut feel.
How Shadow Routing Works
Live Path:- Router receives request
- Routes to current production model
- Response goes to user
- Same request (optionally redacted/trimmed) is mirrored to candidate models
- Responses are tagged with shadow=true and a correlation_id
- Evaluators score quality, latency, and cost asynchronously
- Metrics go into dashboards for promotion decisions
client → router ──► live model ──► user └──► shadow fanout ──► candidates ──► evaluator ──► dashboards
Why Teams Use It
- ✅ Zero user impact: Shadows never touch the live response
- ✅ Evidence-driven: Upgrade on real distribution, not synthetic benchmarks
- ✅ Risk control: Catch regressions (timeouts, hallucinations, policy breaks) early
- ✅ Faster iteration: Test multiple models in parallel without release churn
Key Design Patterns
1. What to Mirror
- Full request clone (default)
- Field-level mirror (mask files, metadata, or long context)
- Transform mirror (normalize prompts for fair comparisons)
2. How to Fan Out
- Single candidate (A/B style)
- Multi-candidate fanout (cap with concurrency + cost budgets)
- Deterministic sampling (stable cohorts by user_id + salt)
3. Delivery Semantics
- Fire-and-forget (never slow down live)
- Hard timeouts for shadows
- Correlation IDs (no shadow side-effects)
4. Data Capture
- Hashes & fingerprints, not raw prompts (by default)
- Track token spend + enforce caps
- Short retention (14–30 days for raw, aggregate long-term)
Sampling Strategies
- Fixed-rate: e.g. 10% of traffic to Candidate A
- Stratified: coverage across intents, languages, user tiers
- Adaptive: increase sampling where uncertainty or gaps appear
💡 Budget sanity check
cost ≈ qps × seconds/day × sample_rate × avg_tokens/1k × $/1k_tokens × num_candidates
Example:
qps=2, sample=0.10, avg_tokens=800, $0.5/1k, candidates=2 → cost ≈
$13.82/day
Privacy Guardrails (Non-Negotiable)
- 🔒 PII redaction: strip emails, phones, names, payment data
- 🔒 Context trimming: limit to what’s necessary
- 🔒 Attachment policy: block or transform sensitive files
- 🔒 Residency + encryption: data stays in approved regions, rotated keys
- 🔒 Short TTL: raw logs ≤ 30 days, metrics only long-term
- 🔒 Safety filters: auto-quarantine toxic/leaky responses
Evaluating Candidates
Dashboards should focus on decision-quality signal:
- Win rate: % candidate beats live on rubric scoring
- Latency: p50 / p95 / p99
- Cost per answer:tokens × $/1k
- Failure rate: timeouts, errors
- Guardrail breach rate: safety issues
Slice by:
- Intent/domain (code, math, chat)
- User tier (free vs. paid)
- Language, prompt length
- Trend over time (drift vs. live)
Promotion Playbook
1. Define gates before the run
- Win-rate ≥ +5–10 points
- Latency p95 ≤ live + Y%
- Cost ≤ budget (or justified premium)
- Safety breach ≤ live
2. Run & Review
- Hold config steady for volume (500–1,000 samples/intent)
3. Canary After Shadow
- Route 5% live traffic for 48–72h
- Watch same KPIs
4. Rollback Ready
- One-click revert to prior model
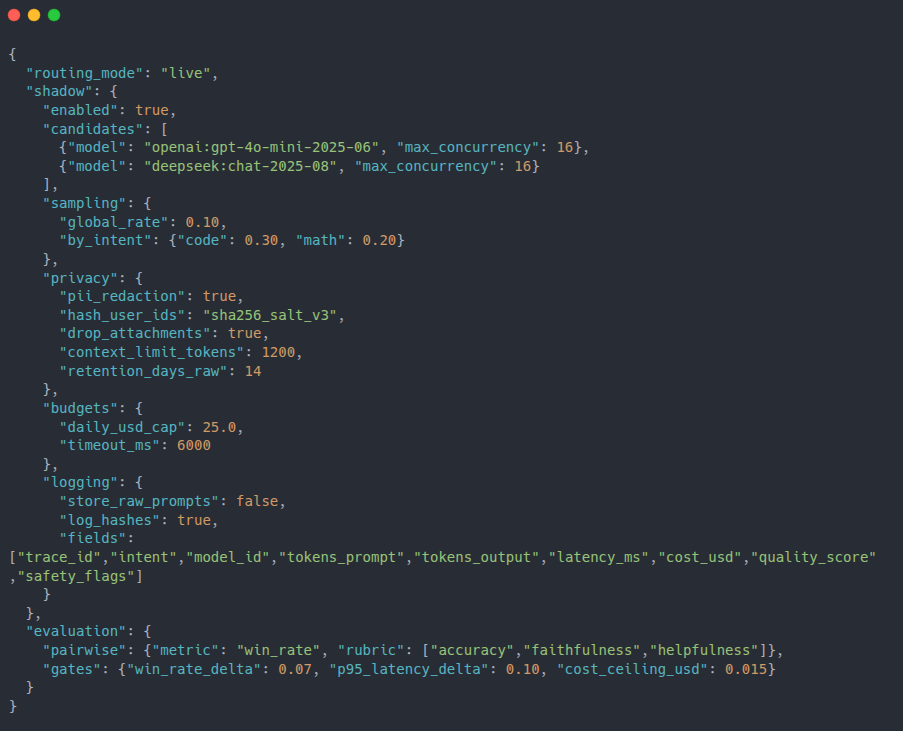
Example Config:
How Kumari AI Helps
Shadow routing is powerful — but hard to build safely in-house.
With Kumari AI, you get it out of the box:
- 🔄 One-click “Shadow Mode”: mirror traffic to candidates without touching your live path
- 🔒 Built-in PII redaction: emails, phones, addresses masked; salted user hashes; raw logs auto-expire
- 📊 Evaluator & dashboards: win-rates, latency tails, cost vs. quality, safety incidents
- 🚦 Promotion guardrails: define gates upfront; generate shareable promotion reports
Quick Start Checklist
- ✅ Define intents & KPIs (win-rate, latency, cost, safety)
- ✅ Pick candidates + set budgets
- ✅ Turn on PII redaction & TTLs
- ✅ Configure sampling (global + intent)
- ✅ Run until each slice has volume
- ✅ Review dashboards, apply gates
- ✅ Canary 5% → monitor 48–72h
- ✅ Promote or rollback
Final Word
Shadow routing lets you trial new models on real traffic — safely,
privately, and with confidence.
If you’d like to enable this in your Kumari AI workspace (with default
guardrails and dashboards ready to go), reach out to us — we’ll help you
get started in minutes.